Announcing: Storyteller v2!
Aug. 31, 2025
At long last, Storyteller v2 has arrived! I’ve been working on this release since April 24:
Since then, I’ve made a lot of changes:
So I wanted to take some time to write about the motivations for all of these changes, what to expect from v2, and what’s next!
What’s new in v2
In short: a lot!
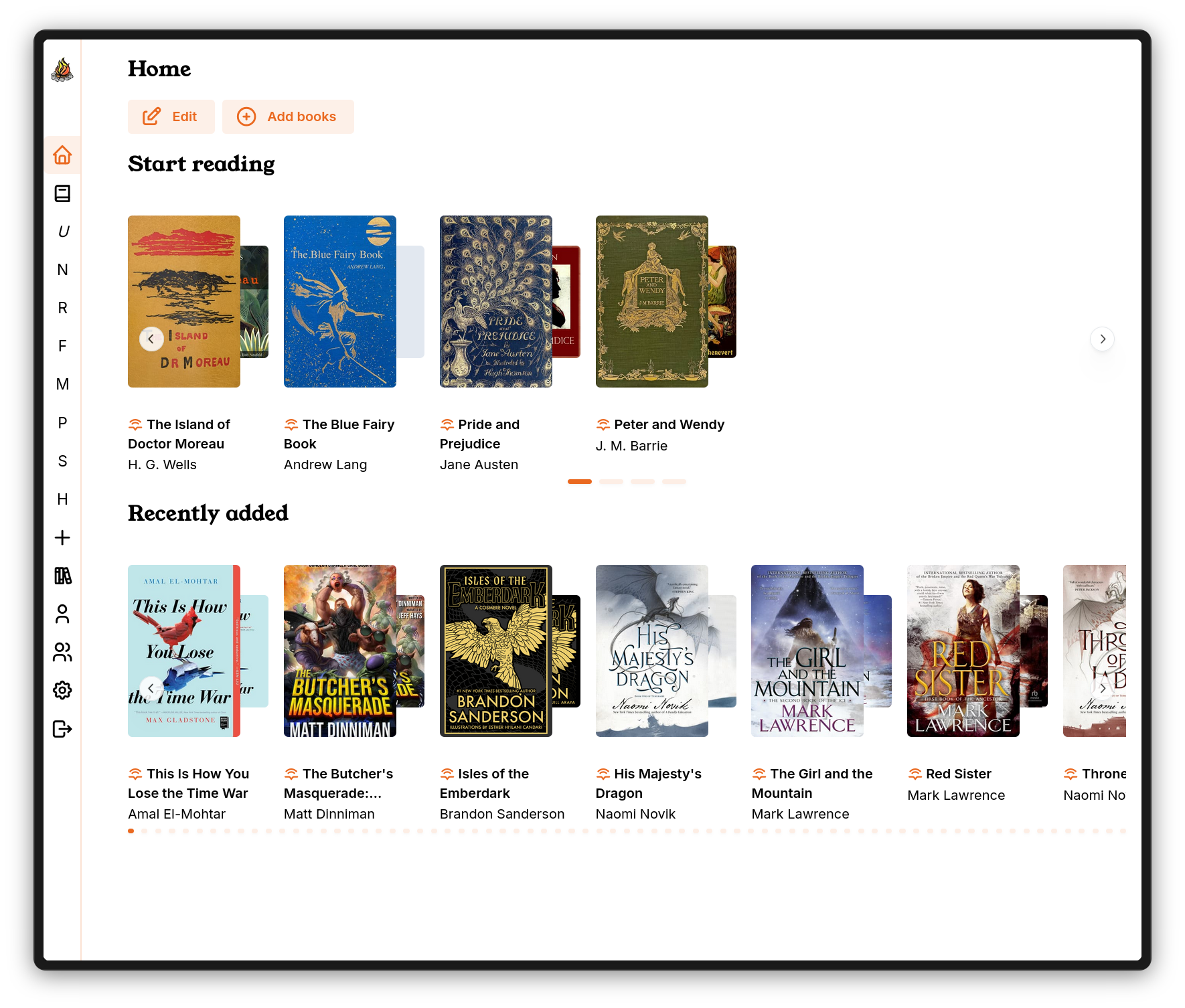
Storyteller is now gunning to be your fully featured ebook, audiobook, and readaloud book library management system. It supports standalone ebooks and audiobooks (with mobile app and web reader/listener support coming soon!), advanced search and sort functions, and a wide array of features for managing your library’s metadata and organizing your collections.
You can organize your books into collections, which can be made public to all of the users on your Storyteller server, or private and shared with only the users you choose. You can organize books by series and tags, and manage metadata like authors and narrators, publication date and description, and more!
Oh, and we support OAuth and OIDC, now! So if you self-host an Authelia instance, or you use Google OAuth to give your family access to your self-hosted services, you can configure your authentication providers directly in the Storyteller settings page.
And even though I put quite a lot of effort into cleaning up Storyteller’s folder structure, Storyteller also now allows you to configure an automatic import folder. Just point Storyteller at the folder with all of your books and watch them magically appear in the app! And, if you do still want to upload your files to Storyteller over HTTP, we now have resumable uploads that are much more robust to lost internet connections and opinionated reverse proxies.
If you want a deeper dive into everything new in v2, check out the docs.
Why v2?
Storyteller uses the “semantic versioning” strategy for determining version numbers. This is true for the Storyteller web server, mobile apps, and software libraries like @smoores/epub. Semantic versioning, or “semver”, breaks version numbers up into three parts: major, minor, and patch. The parts are separated by .s, so the last v1 release of Storyteller, 1.3.6, has a major version of 1, a minor version of 3, and a patch version of 6.
Generally speaking, we increase the patch version when fixing a bug, the minor version when adding new features, and the major version when making a “breaking” change. A breaking change is one that users have to actually do something about — it’s not safe to update to it automatically.
In general, especially with Storyteller, I try to avoid breaking changes. Storyteller is software that is mostly used by people who are not expert software developers, or even expert self-hosters. It’s important to me that Storyteller is as seamless for those users as possible. This means that there were some technical decisions that were made way back in v0.1 of Storyteller that we had been more or less stuck with. These included a very clunky directory structure for assets and a REST API that didn’t match the data model well and followed uncommon patterns.
So when I started working on the “Library Management Features” epic back in April, I quickly found that some of these old design decisions were going to be too awkward to work around if I wanted to be able to build all of these new features into Storyteller. It felt like they’d overstayed their welcome, and it was time to make some changes.
Once I decided that I was going to make backwards incompatible changes to the folder structure and API, it quickly become very appealing to makeevery backwards incompatible change that I thought I would need for the foreseeable future. This meant that the scope of this update was going to be much larger than I had originally intended, but it also meant that I would hopefully be able to lessen the likelihood of future breaking changes.
A new folder structure
First on the chopping block was the old folder structure. Before v1, Storyteller used book titles as folder names, and let me tell you: it was a nightmare. Book titles can (and do) have anything in them: forward slashes, periods, colons, non-Latin characters, you name it. In short, lots of characters that are invalid (or have semantic meaning) in filepaths in at least some operating systems. Also, various operating systems have different maximum lengths for both file path segments and total file paths, and it turns out that some books have very long titles! And what do you do if two books have the same title?
So when v1 rolled around, and I was trying to make everything stable and (relatively) error-free, I decided that I was going to drop the title-based file paths and move to using UUIDs. I also introduced UUIDs as the primary identifier for database records in v1, so I just used those for the folder names, too. On the one hand, this worked perfectly: no conflicts! On the other hand, it wasn’t exactly easy to figure out where your books actually lived:
And yes, you’re reading that correctly: there were separate top-level text and audio directories, so all of the files related to a given book didn’t even live in the same folder.
This was enough of an issue that Storyteller’s product manager started rate limiting herself on how often she would complain about it:
Luckily, I’d had plenty of time since v1 was released to think about how to make it better. First, we needed a strategy for handling collisions when two books had the same title. That ended up not being so bad. We add a suffix field to the database that defaults to an empty string. If we detect that we’re about to create a collision, we set the suffix to the first 6 bytes of the UUID, encoded in base 62:
Even though this is generated deterministically from the UUID, we store it in the database so that in the future we can expose it to users and allow them to modify it.
Then, we needed a strategy for sanitizing filenames. We need to remove any characters that are illegal on (relatively modern) Linux, macOS, or Windows, and ensure that path segments are no longer than 150 bytes.
Now, as long as we make sure to rename all of the relevant files any time the book title changes (slightly easier said than done, but manageable), we should have a much easier time looking for files in our Storyteller folder:
The REST API
Next was the REST API. I won’t get too deep into this, because a lot changed about the API. But at a high level, I wanted to make changes necessary to enable OAuth/OIDC integrations (we were already pretty close to this!), use camel case property names in JSON responses, and generally align the API data models a bit more closely with the database models, which they’d drifted from over time as the data models evolved. Also, I added a ton more endpoints to support all of the new library management features I mentioned above.
The biggest consideration here was that the Storyteller API serves mobile apps as well as the frontend. So even making a v2 release, I couldn’t actually just break the REST API. Instead, I kept around all of the v1 endpoints that the mobile apps used (luckily, the mobile apps only use one update endpoint, and otherwise only read data) and backported all of the changes so that those endpoints served the same interfaces as in v1. All of the new endpoints, including the new versions of the v1 endpoints that were sticking around, went in a new /v2/namespace.
Other technical changes
As the scope of the Storyteller web server grew from a barebones interface for uploading books and aligning them into a full blown library management system, I started leveling up the infrastructure a bit. In the v1 codebase, I was hand-writing all of my SQL queries as strings. Now we use kysely, which is quickly becoming one of my favorite libraries. The frontend, which was very simple in v1 and relied quite a bit on Server Components, ended up with a lot more client state in v2, and so I added Redux Toolkit, and specifically RTK Query for managing client and server state. I also added Auth.js for all of the OAuth/OIDC integrations, which trivialized what would have otherwise been a massive undertaking.
I was also increasingly glad that I’d added the Mantine design system in v1, because v2 is considerably more interactive than v1. Mantine hasn’t let me down so far — I highly recommend it!
Mini-announcement: Storyteller is on ElfHosted!
By the way! I haven’t written about it publicly yet, partly because we were waiting on some of the v2 features to make the user experience better, but Storyteller is now on ElfHosted! Like PikaPods, ElfHosted is a platform that runs self-hostable apps for you, taking over the maintenance burden of actually owning and managing physical hardware, without sacrificing ownership over your data and software. And like PikaPods, every Storyteller instance on ElfHosted helps support future Storyteller development!
On the horizon
I would say now it’s time for a well deserved break. To rest on my laurels for a bit, spend time with my family and friends, sleep. But we all know I’m going to push a new release tomorrow, so who am I really kidding?
Here’s what you can expect in the near future from Storyteller (in roughly priority order, though of course if folks want to contribute features out of order, I won’t stop them!):
Mobile apps v2
This v2 release opens up several doors for an improved mobile experience, and I want to bring those improvements to the mobile apps as soon as possible. Filters and search, “smart shelves”, standalone audiobooks and ebooks, and more.
AI generated audio
I am a huge proponent of purchasing real audiobooks, especially from awesome, DRM-free audiobook stores like Libro.fm. A good audiobook is its own work of art, and its creators should absolutely be compensated for their labor.
But not every book has a companion audiobook! So Storyteller is going to add support for generating audiobooks using generative AI, to fill in the gaps for users that read a lot of books that tend not to have accompanying audiobooks.
A web reader
This is a very long-awaited feature for many Storyteller users, and it’s a pretty big one, too! We’re planning on adding a web-based reader, so that users can have a solid, fully featured immersive reading experience on desktop.
Even more library management features!
That’s right, I know some of you media hoarders are looking at the current library management feature set and thinking “This is never going to meet my needs!” But think again! We’ve already got a moderately long list of additional library management features we want to add, like automatic metadata and cover art ingestion, ratings, and more sort and filter options.
Gratitude
I can’t possibly express how grateful I am to all of the folks that make up Storyteller’s beautiful community. I feel so honored to be able to share this thing I made with you all, and I love hearing from you about your experiences with Storyteller (good and bad!).
In particular, I need to give a huge thank you to Jess, Storyteller’s product manager, who continues to push Storyteller to be the best software it can possibly be. Another huge thank you goes to everyone that contributed bug fixes and features to v2, as well as all of the alpha testers that helped me find the truly hundreds of bugs, big and small, that we squashed before launch. And the several that we found after launch, too.